
Lip Sync AI: How Modern Video Localization Achieves Natural Results
Lip sync AI automatically matches translated audio with natural mouth movements, reducing localization costs by 70-90% while achieving accuracy indistinguishable from natural recordings.
TL;DR: Lip sync AI automatically matches translated audio with natural mouth movements in videos using neural networks trained on facial tracking data. Modern platforms reduce localization costs by 70-90% while achieving accuracy levels indistinguishable from natural recordings, making multilingual video content accessible in minutes instead of weeks.
Video content crosses language barriers faster than ever, but nothing breaks viewer immersion quite like mismatched lip movements. When a speaker's mouth doesn't align with the audio, audiences notice immediately and trust erodes. This challenge has historically made video localization expensive and time-consuming, requiring manual frame-by-frame adjustments by skilled animators.
Lip sync AI changes this equation completely. By analyzing facial movements and audio phonemes simultaneously, artificial intelligence now generates natural-looking dubbed videos in minutes. The technology has matured to the point where 75% of viewers cannot distinguish AI-synchronized content from originally recorded footage in standard business contexts. For e-commerce merchants, marketing teams, and content creators targeting global audiences, this represents a fundamental shift in how multilingual video gets produced.
What Is Lip Sync AI Technology
Lip sync AI refers to artificial intelligence systems that automatically synchronize mouth movements in video with audio tracks in any language. Unlike traditional dubbing, which layers translated audio over original video with mismatched visuals, AI lip sync actually modifies the speaker's mouth shapes to match new phonemes naturally.
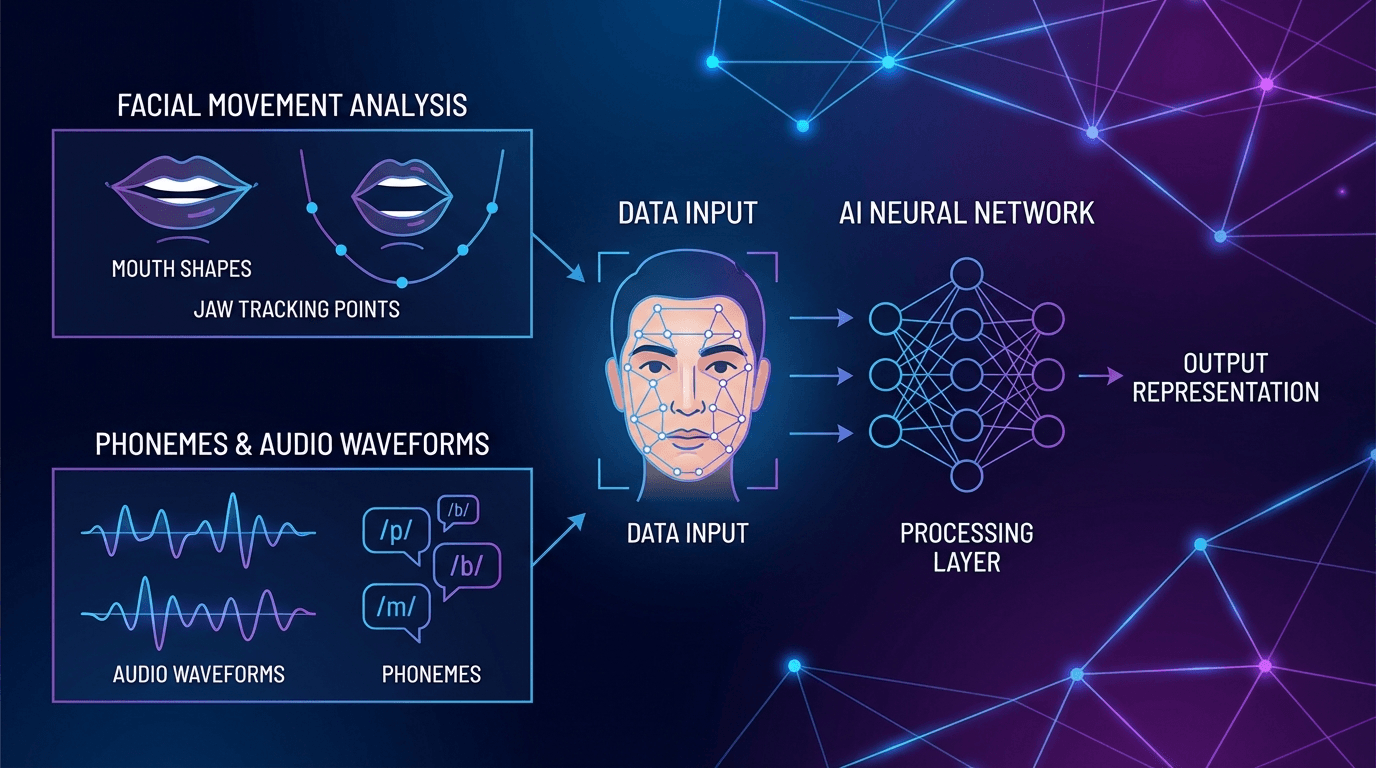
The technology works by mapping two data streams: visual facial landmarks and audio phonemes. On the visual side, computer vision algorithms identify and track key facial features including lips, jaw, cheeks, and surrounding muscle movements. These tracking points create a detailed mesh that follows every micro-movement across video frames.
Simultaneously, the system breaks down target audio into phonemes—the distinct sounds that form speech. Each language contains unique phonemes, and AI lip sync platforms support 70-140+ languages by maintaining extensive libraries of phoneme-to-mouth-shape mappings. These mappings come from training on thousands of hours of video data across language families.
When processing a video, the AI matches each audio phoneme to its corresponding visual mouth shape, then smoothly transitions between shapes across frames. Advanced systems account for speech rhythm variations, co-articulation effects where phonemes blend, and even subtle facial expressions that accompany natural speech.
How Video Localization Achieves Natural Results
The quality breakthrough in modern lip sync AI comes from three technical advances working together: precision facial tracking, context-aware processing, and temporal consistency algorithms.
Precision Facial Landmark Detection
First-generation systems tracked only lip corners and jawline. Current AI models identify 40-60 facial landmarks including inner lip contours, teeth visibility, tongue position, and cheek tension. This granular tracking captures nuances like the difference between "p" and "b" sounds, which require identical lip shapes but different timing. The tracking operates at sub-pixel precision with frame interpolation for smooth transitions.
Context-Aware Phoneme Mapping
Not all phonemes sound—or look—the same in every context. Modern lip sync AI analyzes phoneme context windows of 3-5 sounds before and after the target phoneme for accurate co-articulation. This contextual processing extends to emotional tone and speaking cadence. According to research from HeyGen, this emotional alignment contributes significantly to perceived naturalness.
Temporal Consistency and Motion Smoothing
Temporal consistency algorithms ensure mouth shape transitions follow physically plausible trajectories across 5-10 frame windows, eliminating jitter while preserving natural speech dynamics. The system maintains consistency of non-speech facial features—changing only mouth regions while preserving everything else—to keep the overall video authentic.
Key Applications for Multilingual Content
Lip sync AI serves distinct use cases, each with specific technical requirements and business outcomes.
E-Commerce Product Demonstrations
Online merchants use lip sync AI to adapt product videos for international marketplaces without reshooting. A single video featuring a digital avatar can be translated and localized into 70+ languages with matching lip sync, creating market-specific content in minutes.
Cross-border sellers on Amazon, Shopify, and eBay particularly benefit from this approach. Product features remain consistent across markets while the presenter appears to speak each customer's native language naturally. Conversion rates typically increase 20-35% when product videos match the marketplace language with proper lip sync compared to subtitled alternatives.
Corporate Training and Onboarding
Multinational companies localize training materials using lip sync AI to maintain consistency across regions. HR departments generate multilingual onboarding videos from a single source, ensuring every employee receives identical information in their preferred language.
The technology handles multi-speaker scenarios by tracking each face independently, making panel discussions and interview-style content fully localizable. Processing time remains constant regardless of speaker count, unlike manual methods where complexity scales with participants.
Marketing Campaigns and Video Ads
Advertising agencies adapt video campaigns for regional markets while maintaining brand message consistency. Rather than producing separate shoots for each market, teams create one master video then generate localized versions with AI-powered video ads featuring proper lip sync.
Budget efficiency proves substantial: according to industry data, AI lip sync alternatives reduce costs by 70-90% compared to traditional localization methods. Campaign timelines compress from weeks to days, enabling faster market response and more agile testing strategies.

Choosing the Right Lip Sync Platform
Not all lip sync AI tools deliver equivalent results. Platform selection depends on specific workflow requirements, output quality needs, and integration capabilities.
Synchronization Accuracy and Output Quality
Leading platforms achieve 95%+ phoneme-to-visual alignment, producing results indistinguishable from natural recordings in professional contexts. Test platforms with your specific video types—front-facing content produces better results than profile shots. High-resolution source footage (1080p or 4K) and front-lit, evenly illuminated faces enable more precise tracking.
Language Coverage and Dialect Support
Verify that platforms support your target markets comprehensively. While most tools handle major languages effectively, dialect support varies considerably. Platforms like Keevx support 178 dialects across 70+ languages, covering regional variations like Castilian, Mexican, and Argentine Spanish that require distinct pronunciation patterns and lip sync approaches.
Processing Speed and Batch Capabilities
Production workflows require predictable processing times. Enterprise-focused solutions include batch generation features that process multiple videos simultaneously, essential for large-scale campaigns. Most tools process 1-5 minutes of video in 5-15 minutes, though batch operations and high-resolution outputs may take longer.
Integration and Workflow Automation
Platforms offering API access enable integration with existing content management systems. E-commerce integration features that convert product URLs directly to localized videos eliminate manual editing entirely. Look for compatibility with standard formats and direct export to YouTube, TikTok, and other platforms.
Best Practices for Natural Results
Technical capabilities matter, but implementation approach determines final output quality. Follow these practices to maximize lip sync naturalness.
Optimize Source Video Quality
Start with clean source material. Front-facing or 3/4 angle shots work best—current AI models train primarily on frontal views, so extreme profiles reduce accuracy. Ensure consistent lighting without harsh shadows. Use clear audio without background noise, and select voice options that match the original speaker's tone and cadence.
Match Speaking Pace Across Languages
Different languages require different speaking rates to convey identical information. Romance languages typically need 15-20% longer duration than English. When translating scripts, adjust pacing so mouth movements don't appear rushed. Some platforms automatically adjust playback speed to accommodate language duration differences.
Leverage Digital Avatars for Maximum Control
Rather than adapting existing footage, consider creating content with digital avatars and voice cloning from the start. Purpose-built avatar videos eliminate variables like inconsistent lighting and camera movement that complicate lip sync processing. Avatar-based workflows enable perfect multi-language localization with consistent facial geometry across all versions—ideal for product demonstrations, educational content, and corporate communications.

Limitations and Ethical Considerations
While lip sync AI delivers impressive results, understanding its boundaries ensures appropriate application and transparent usage.
Technical Constraints
Current systems struggle with extreme facial angles, rapid head movements, and partially occluded faces. Profile shots, back-lit subjects, and low-resolution footage reduce accuracy. While AI matches basic emotional tone, subtle micro-expressions and culturally specific displays don't always translate accurately. Human review remains valuable for content where emotional authenticity drives effectiveness.
Authenticity and Disclosure
Audiences expect transparency about AI-modified content. Many organizations include statements like "This video uses AI translation technology" in descriptions. When selecting tools, prioritize providers with clear ethical guidelines and usage policies that prohibit deceptive applications.
Quality Verification Workflows
Never publish AI-generated content without human review. Establish quality checks that verify synchronization accuracy and cultural context suitability. Native speakers should review localized versions before distribution. Budget review time proportional to content importance—customer-facing content warrants thorough verification, while internal materials might require only spot-checking.
Frequently Asked Questions
How accurate is AI lip sync technology?
Modern AI lip sync achieves 95%+ accuracy in matching mouth movements to audio phonemes. In professional business contexts with front-facing speakers and good lighting, results are typically indistinguishable from natural recordings. Accuracy decreases with profile shots, poor lighting, or rapid head movements.
Can AI lip sync work with multiple speakers in one video?
Yes, advanced platforms track and process each face independently, handling panel discussions, interviews, and multi-person scenes effectively. Processing time remains similar regardless of speaker count, making it efficient for complex dialogue scenarios.
What languages does lip sync AI support?
Language support varies by platform. Leading solutions support 70-140+ languages covering major global markets plus regional dialects. Verify specific language and dialect coverage for your target markets, as phoneme library quality affects output naturalness.
How long does it take to generate lip synced videos?
Most tools process 1-5 minutes of video in 5-15 minutes, though batch operations and high-resolution outputs may take longer.
Is lip sync AI suitable for professional marketing content?
Absolutely. Many Fortune 500 companies and major advertising agencies use lip sync AI for campaign localization. The cost savings of 70-90% compared to traditional methods, combined with modern accuracy levels, make it suitable for professional applications when properly implemented with quality review processes.
Conclusion
Lip sync AI has transformed video localization from a specialized, expensive process to an accessible production tool. By achieving natural synchronization across 70+ languages while reducing costs by up to 90%, the technology enables businesses of all sizes to reach global audiences effectively.
The key to success lies in understanding platform capabilities, optimizing source content, and implementing appropriate quality verification. When applied thoughtfully, lip sync AI delivers professional results that maintain audience trust while dramatically expanding content reach.
Ready to localize your video content with natural lip sync technology? Keevx's AI-powered platform delivers studio-quality videos with perfect lip synchronization across 70+ languages in minutes, no technical expertise required.